InGoogle Cloud - CommunitybyOscar PulidoStop Thinking in Data Pipelines, Think in Data Platforms: Introducing the Analytics Engineering…Imagine a world where you could deploy your entire enterprise-ready data platform in minutes and empower your data practitioners to…Oct 28, 20244Oct 28, 20244
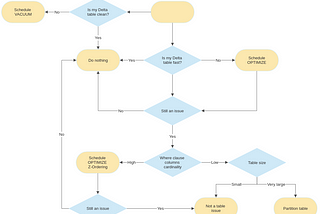
InLevel Up CodingbyYousry MohamedDelta Lake Liquid Clustering — A visual explanationHow to optimize lakehouse data storage layout with minimal effort.Jan 28, 20243Jan 28, 20243
Steve RussoUse Rust to Write Spark AppsUntil Spark 3.4, developing and deploying a Spark application was sometimes a big hassle. Getting Spark running locally for development…Jul 3, 2024Jul 3, 2024
InTDS ArchivebyBernd WesselyChallenges and Solutions in Data Mesh — Part 2“Data as a Product” is a core principle in Data Mesh. Why the current definition needs adaptation to fully enable the mesh.May 17, 20242May 17, 20242
InDBSQL SME EngineeringbyDatabricks SQL SMEOne Big Table vs. Dimensional Modeling on Databricks SQLWhy to use each and best practices in Databricks SQLMay 6, 20245May 6, 20245
InThe PayPal Technology BlogbyIlay ChenLeveraging Spark 3 and NVIDIA’s GPUs to Reduce Cloud Cost by up to 70% for Big Data PipelinesHow PayPal achieved a remarkable cloud cost reduction through strategic GPU utilizationFeb 21, 20247Feb 21, 20247
Barr MosesWhen a Data Mesh Doesn’t Make Sense for Your OrganizationData mesh requires the right mix of process, tooling, and internal resource to be effective. Find out what it takes to get data mesh-ready.Feb 26, 20248Feb 26, 20248
InTowards AIbyMuttineni Sai RohithStart using Liquid Clustering instead of Partitioning for Delta tables in DatabricksLiquid clustering replaces table partitioning and ZORDER to simplify data layout decisions and optimize query performanceNov 17, 2023Nov 17, 2023
InSnowflake Builders Blog: Data Engineers, App Developers, AI/ML, & Data SciencebyPhani RajUnderstanding Iceberg Table MetadataDated: 30-Jan-2023Jan 31, 20232Jan 31, 20232
Shingo OKAWAOpenTableHub: Data Sharing Platform #1I am currently working on a project named OpenTableHub for a data-sharing social networking service platform. In this series, I would like…Nov 29, 2023Nov 29, 2023
Scott HainesWorking with Spark SQL Time FunctionsA Hands-On Guide to Time with Apache SparkMar 7, 2023Mar 7, 2023
InDev GeniusbyApache DorisReplacing Apache Hive, Elasticsearch and PostgreSQL with Apache DorisSimplicity is the best policy.Jun 15, 20231Jun 15, 20231
InTDS ArchivebyMahdi KarabibenWriting design docs for data pipelinesExploring the what, why, and how of design docs for data components — and why they matter.May 22, 20231May 22, 20231
InLevel Up CodingbyLuís OliveiraPolars vs PySpark: Testing with Middle Size DataChecking execution timeMay 5, 20234May 5, 20234
InTDS ArchivebyMahmoud HarmouchRust: The Next Big Thing in Data ScienceA Contextual Guide for Data Scientists and AnalystsApr 24, 202316Apr 24, 202316
Yousry MohamedDelta lake Z-Ordering from A to ZUnderstand how to optimise delta lake tables for high cardinality queries.Sep 19, 20225Sep 19, 20225
InBetter ProgrammingbySteve RussoI Asked ChatGPT to Build a Data Pipeline, and Then I Ran ItYour job might be safe. For now…Apr 5, 202310Apr 5, 202310
Ben RogojanWhy Is Polars All The RageBy Daniel Beach author of Data Engineering CentralMar 16, 20236Mar 16, 20236
InTDS ArchivebyVitor TeixeiraDelta Lake— Keeping it fast and cleanEver wondered how to improve your Delta tables’ performance? Hands-on on how to keep Delta tables fast and clean.Feb 15, 20235Feb 15, 20235
Abhijit MenonUsing ChatGPT3 as a Data EngineerThe world has gone pretty crazy about ChatGPT3, while I was skeptical about it being useful for day-to-day data engineering use cases, that…Dec 24, 20225Dec 24, 20225